Introduction
In this chapter, we will explore how to create and simulate agents in a virtual environment using the OpenAI Gym toolkit, specifically the MountainCar-v0 environment. We will also build a simple rule-based system for decision-making, guiding our agent toward achieving the goal of the simulation.
By the end of this chapter, you will understand:
- How to build agents that interact with the environment.
- How to create rule-based systems to control agent behavior.
- How to compare different strategies using data visualization.
- How to use the Gym environment to simulate tasks.
Gym is a toolkit for developing and comparing reinforcement learning algorithms. It provides a variety of simulated environments (such as games, physics simulations, or robot control tasks), including MountainCar-v0.
Mountain Car Problem:
It is a simple problem where a car must drive up a steep hill:
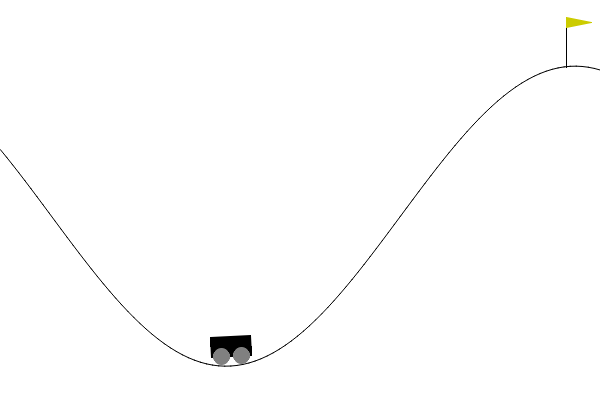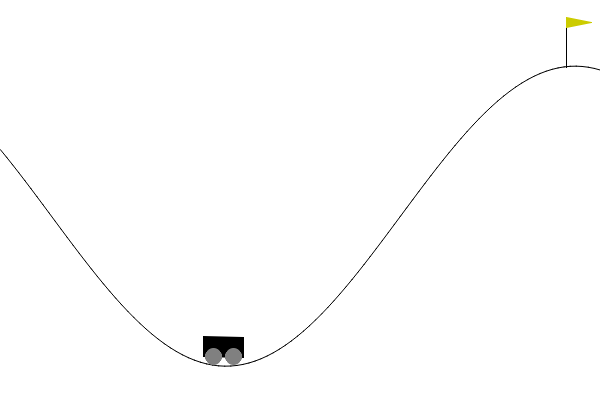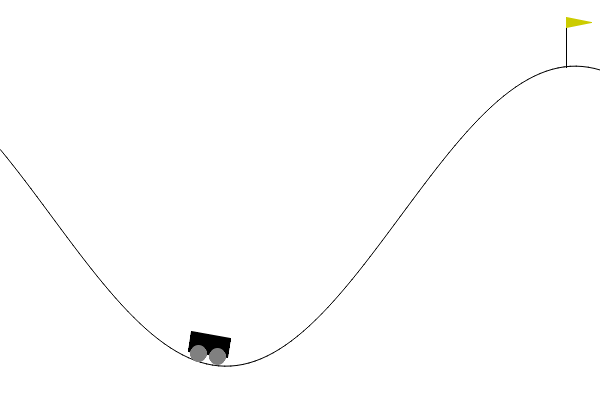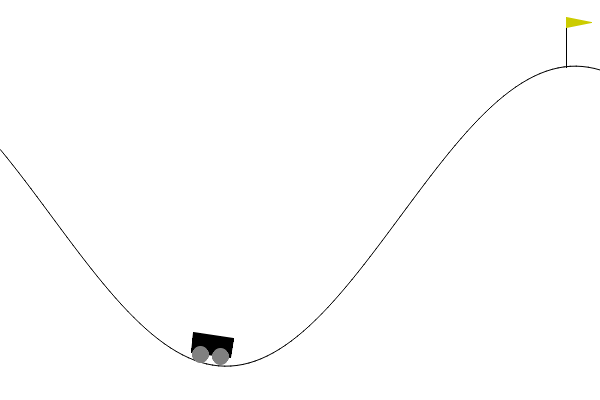
The car sits between two hills, and the goal is to get to the top of the right hill. The car's engine is too weak to drive directly up, so it must build momentum by driving back and forth.
The terminology used here applies to any rule-based system for decision-making: Agent, Action, State.
In our case, the Agent is the car.
At each step of the simulation, the agent can take one of three Actions:
- Push left (action 0)
- Do nothing (action 1)
- Push right (action 2)
Note: The number associated with the actions (0,1,2) comes from the Action Space defined by the Gym API.
The State of the agent is represented as an array:
Observation = [position, velocity]
where position is the car’s horizontal position and velocity is its current speed.
Observation Space:
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | position of the car along the x-axis | -1.2 | 0.6 |
| 1 | velocity of the car | -0.07 | 0.07 |
Now, let's simulate different strategies for moving the car up the hill using Gym.
Importing Libraries
Here are the libraries we will be using in this exercise:
import numpy as np
import matplotlib.pyplot as plt
import gymnasium as gym
NumPy-> NumPy module, widely used for numerical operations, especially for handling arraysmatplotlib.pyplot-> Matplotlib's pyplot module, which is used to create visualizations like the boxplot later in the codegymnasium-> Gymnasium (formerly Gym) is a toolkit for developing and comparing reinforcement learning algorithms. It's used to simulate the MountainCar-v0 environment.
Depending on your setup, you may need to install the following packages:
pip install gymnasium
pip install swig
or alternatively, use the Python distribution like Anaconda, which comes with the packages pre-installed.
Simulation Configuration
Next, we will set up the environment using gym.make(). (Refer to Gym API doc for more details)
import gymnasium as gym
env = gym.make("MountainCar-v0", render_mode="human")
observation, info = env.reset()
for _ in range(1000):
action = env.action_space.sample() # agent policy that uses the observation and info
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observation, info = env.reset()
env.close()
You should now be able to run the program and see the simulation.
e.g. run the simulation:
python gym.py
The car should be moving back and forth, but struggling to reach the top.
Creating a Rule-Based System
Let's now guide our agent to drive up the hill using a rule-based system.
A quick recap:
A rule-based system is a set of rules that dictate what action to take depending on the current state of the environment. Unlike learning-based approaches, our system uses fixed rules that we define in advance.
Here are some possible strategies for action selection:
- Random Action: The agent selects actions randomly from the available options.
- Always Push Right: The agent always pushes to the right, regardless of the situation.
- Two-Rule System: The agent uses a simple rule based on position and velocity to decide whether to push left, right, or do nothing.
- Four-Rule System: A more complex set of rules based on position and velocity to make more refined decisions.
Let’s define the function to select actions based on the strategy.
def select_action(action_selection_code, observation):
"""
Selects an action based on the action_selection_code and current observation.
Parameters:
action_selection_code (int): Strategy to choose an action (0, 1, 2, or 3).
observation (array): Current state observation [position, velocity].
Returns:
action (int): The selected action.
"""
position, velocity = observation[0], observation[1]
if action_selection_code == 0:
# Random action
return env.action_space.sample()
if action_selection_code == 1:
# Always push to the right
return 2
if action_selection_code == 2:
# Two-rule system
if position > POSITION_CENTRE and velocity > 0:
return 2 # Push right
elif position < POSITION_CENTRE and velocity < 0:
return 0 # Push left
else:
return 1 # Do nothing
if action_selection_code == 3:
# Four-rule system
if position > POSITION_CENTRE and velocity > 0:
return 2 # Push right
elif position < POSITION_CENTRE and velocity < 0:
return 0 # Push left
elif position < POSITION_CENTRE and velocity > 0:
return 2 # Push right
elif position > POSITION_CENTRE and velocity < 0:
return 0 # Push left
else:
return 1 # Do nothing
# Default action
return 1
Running Multiple Agents with Different Strategies
To observe how well each strategy performs, we can simulate multiple agents, each using one of the four strategies. Here, we will simulate 100 agents. For each agent, we allow up to 200 iterations (steps) to complete the task.
Simulating Agents
# Constants for simulation configuration
MAX_ITERATIONS = 200 # Maximum number of steps per episode
NUM_AGENTS = 100 # Number of agents to test each strategy
NUM_STRATEGIES = 4 # Number of action-selection strategies
def simulate_mountain_car():
"""
Simulates the MountainCar-v0 environment with multiple agents and strategies.
This function compares the performance of different action-selection strategies
and plots the number of steps each strategy takes to complete the task.
"""
print("Starting Mountain Car Simulation")
# Initialize the MountainCar environment
env = gym.make("MountainCar-v0", render_mode="human")
observation, info = env.reset()
# Array to store the number of steps taken by each agent for each strategy
steps_taken = np.zeros((NUM_AGENTS, NUM_STRATEGIES))
# Loop over all strategies
for strategy in range(NUM_STRATEGIES):
# Test each agent with the current strategy
for agent in range(NUM_AGENTS):
for step in range(MAX_ITERATIONS):
# Select action based on the strategy and current observation
action = select_action(strategy, observation)
# Take a step in the environment
observation, reward, terminated, truncated, info = env.step(action)
# If the episode ends (goal reached or time limit exceeded), reset the environment
if terminated or truncated:
observation, info = env.reset()
break
# Store the number of steps taken by the agent for the current strategy
steps_taken[agent][strategy] = step
# Plot the results using a boxplot
plot_results(steps_taken)
print("Closing the environment")
env.close()
Visualization
Finally, let's visualize the results. We’ll use a boxplot to compare how many steps each strategy takes to complete the task.
import matplotlib.pyplot as plt
def plot_results(steps_taken):
"""
Plots the number of steps taken for each strategy using a boxplot.
Parameters:
steps_taken (ndarray): A 2D array where each row corresponds to the steps
taken by an agent for a particular strategy.
"""
plt.figure(figsize=(8, 6))
plt.boxplot(steps_taken, showmeans=True)
plt.title("Number of Steps to Complete the Task by Strategy")
plt.xlabel("Strategy")
plt.ylabel("Number of Steps")
plt.xticks(np.arange(1, NUM_STRATEGIES + 1), ['Random', 'Always Right', 'Two Rules', 'Four Rules'])
plt.grid(True)
plt.show()
The plot_results() function will generate a boxplot that shows how many steps each agent took for each strategy. You’ll be able to compare the performance of the different strategies based on this visualization.